最近看几家HIT厂商在说自己遵循了openEHR标准规范去做了一些应用,包括个人健康档案、集成平台、临床数据仓库、电子病历等等,不一而足。那些厂商到底是应用openEHR解决了一些现实问题呢,还是在整宣传噱头呢?我基于自己的理解,谈一谈openEHR到底适合干什么。
openEHR的起源
EHR是电子健康档案的英文缩写,openEHR原本就是一套开源的电子健康档案规范,它是发源于欧洲的GEHR(Good Europe Health Record),最开始的目的是支撑欧洲健康远程信息通讯。上个世纪末,有人基于GEHR的研究成果,提出了openEHR的概念,期望建立一个开源的电子健康档案规范。后来专门的openEHR机构成立了,openEHR机构的主要是目标是通过研究临床需求、建立标准与实施软件,实现开放的、支持互操作的健康处理平台,以加快促进高质量的EHR的发展。经过了十几年的发展,到了2010年后openEHR被引入了中国,
openEHR规范概述
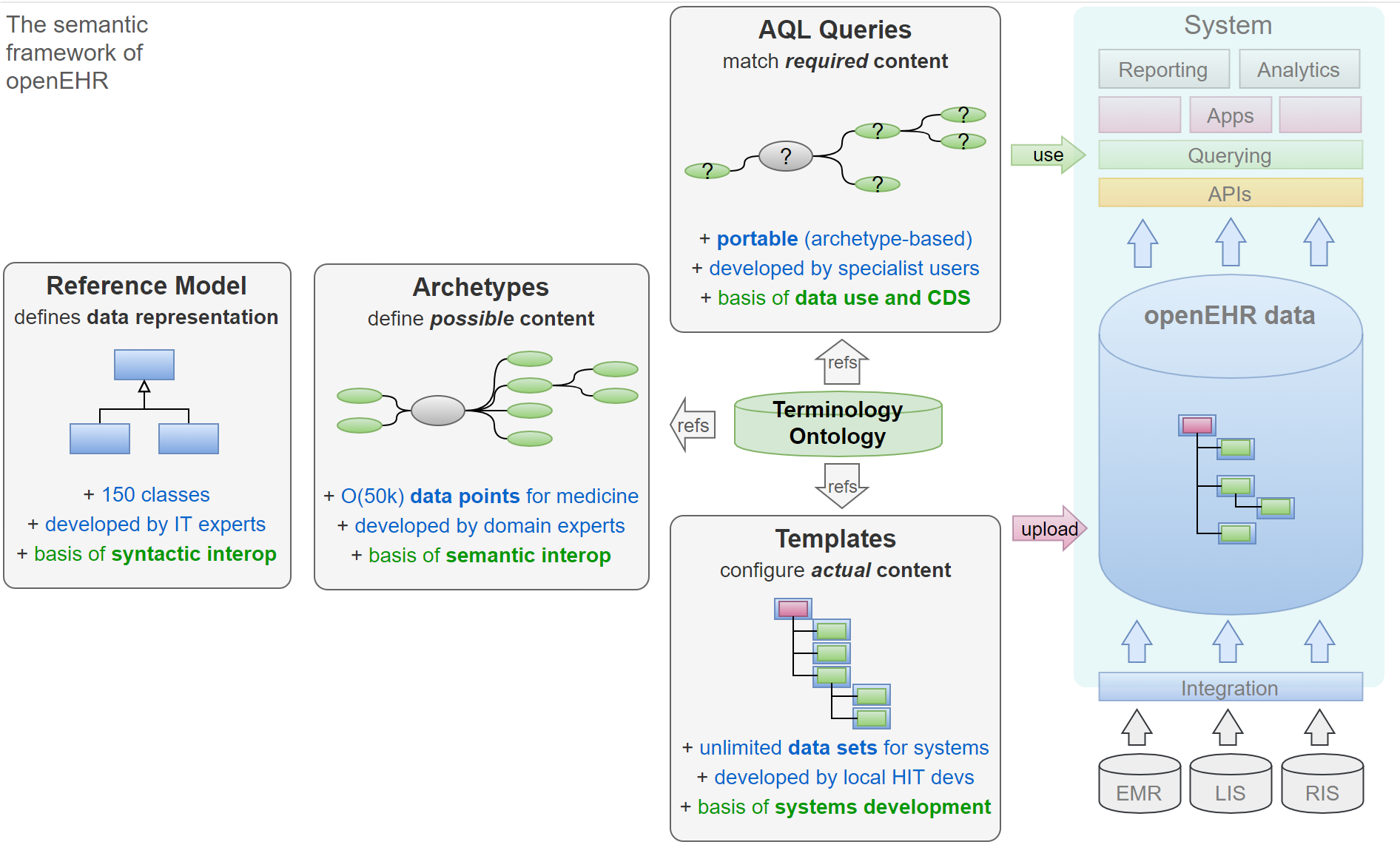
openEHR最核心的概念就是RM \ AM,以及EHR、COMPOSITION、SECTION、ENTRY四类对象。
先讲EHR、COMPOSITION、SECTION、ENTRY。这些概念是源于GEHR项目的。COMPOSITION可以理解为document,多个document组成一份EHR。COMPOSITION本身可以包含若干个content,这些content可以是SECTION也是是ENTRY。SECTION可以包含若干个ENTRY或者SECTION。
RM是参考模型,是技术层面的定义,比如基础包的定义,支持的数据类型的定义,支持的数据结构的定义,安全信息定义,EHR、COMPOSITION、SECTION、ENTRY四类对象的关系等等。ENTRY是最小的实体,ENTRY下面包含的信息大体分为两类:诊疗类和管理类。诊疗类还可以细分为观察、评估、只是、执行四类业务活动信息。所以RM是纯技术的,不带具体医疗业务的。
AM是原型模型,是业务层面的定义,可以直接理解成一个个领域模型。每个openEHR的原型定义了一种临床概念,比如处方、血压、诊断等等,原型模型定义该原型需要存储的数据内容和形式(也就是前面RM支持的)。原型是使用ADL定义的。目前openEHR已经积累了大概500个左右的原型库可直接引用。
这种RM和AM的设计,就是openEHR机构一直强调的将知识与技术剥离的分层方法。让业务专家去设计原型,让技术人员根据参考模型去开发软件工具。然后最终通过选取不同的原型来组合起来(openEHR称之为模板)支撑应用。
openEHR适用场景
正如在前面阐述的一样,openEHR它本质上是用领域模型的方法去表达医疗业务。按照业务领域的信息聚合必然使得其对医疗业务人员友好。我理解“处方”,不用去查看,就知道处方这个原型下,必然有什么。如果我对整个医疗业务都熟悉,那么我很容易在整个体系内找到我需要的信息。因为整个过程只取决于业务理解,而非技术设计或工程实现。
当openEHR作为一个公开的标准时,那么它就成为一个大家都可以理解的信息定义,在交换传输中就省略了定义声明这一步,简化了对接的步骤。但是,我们得看到目前openEHR的原型大多来自于西方,而欧洲、澳大利亚等的医疗体系与我国还是有很大差别的,所以原型库中的原型肯定有不适用的地方,因此想做到不声明即互知这一步,还需要形成中国的原型库。
openEHR的持久化存储有很多种方式,一种是按照参考模型对象关系来存储数据,另一种是按照属性/路径来存储数据(这种是openEHR机构推荐的),还可以按照原型关系来存储数据。但无论这三种方法的哪一种,在面临数据量级稍微大一点的复杂条件关联的批量查询,必然性能较低——这是受限于openEHR的特性——当它将技术实现与业务知识分离时,当它按照一个个领域实体固化了对象时,就已经埋下了因。至于国内还有人建议通过模板定义以周期性的频率来执行ETL过程在openEHR存储之上生成多维数据集市,只能算时治标,可能在某些场景下可行,但改变不了这个现实。
所以总的来说,openEHR适合的场景有:
- 跨实体的医疗数据交换协议。如医疗机构之间的互联互通。
- 有固定路径的精确查询。如患者360视图,个人健康档案应用。
- 个体健康信息的有层次的组织存储。如个人健康档案存储。
openEHR不适合的场景有:
- CDR、HDW等面向分析的数据中心
- 面向交易的医疗业务信息化系统