
阿里巴巴数据新能源架构解读
2017全球机器学习技术大会上阿里巴巴从什么是数据新能源说起,接着介绍了阿里目前比较成功的两款数据产品,一个是是自动化标签生产,另外一个是大规模分布式知识图谱,以及在此之上的一些重要应用,其中讲到了他们的技术架构,下文是Lefer对其架构的理解。
总体技术架构
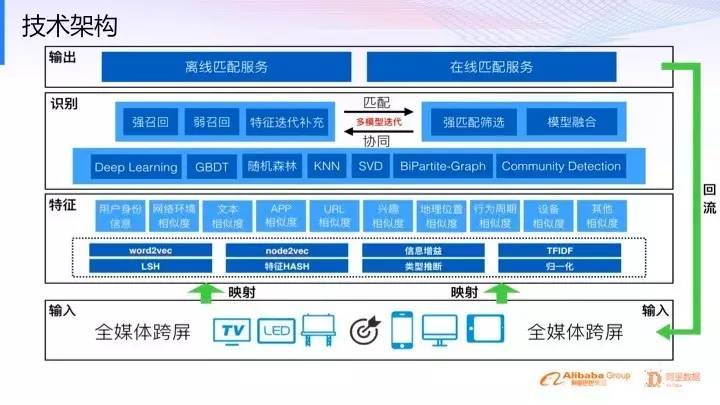
整体分为输入,特征,识别,输出四个层次。
输入:各种用户终端产生并采集到的数据
特征:分为技术和特征两类。技术是指各种特征的提取算法,特征是指计算所输出的有价值的维度。
word2vec:解析自然语句,在向量空间内将词的向量按相似性进行分组。word2vec神经网络的输出是一个词汇表,其中每个词都有一个对应的向量,可以将这些向量输入深度学习网络,也可以只是通过查询这些向量来识别词之间的关系。Word2vec衡量词的余弦相似性,无相似性表示为90度角,而相似度为1的完全相似则表示为0度角,即完全重合;例如,瑞典与瑞典完全相同,而挪威与瑞典的余弦距离为0.760124,高于其他任何国家。
node2vec:主要用于处理网络结构中的多分类和链路预测任务,具体来说是对网络中的节点和边的特征向量表示方法。简单来说就是将原有社交网络中的图结构,表达成特征向量矩阵,每一个node表示成一个特征向量,用向量与向量之间的矩阵运算来得到相互的关系。
个人理解word2vec和node2vec的区别在于word2vec识别的是点的向量值,node2vec是线的向量值
信息增益:信息增益是特征选择中的一个重要指标,它定义为一个特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。信息增益是针对一个一个的特征而言的,就是看一个特征t,系统有它和没它的时候信息量各是多少,两者的差值就是这个特征给系统带来的信息量,即增益。对于决策树来说,信息增益越大的特征值越靠近根节点,那么整个树就越简洁。
TF-IDF:tf是词频的意思,idf是逆向文件频率。是一种用于信息检索与文本挖掘的常用加权技术。tf-idf是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。tf-idf加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。可以举例理解:如果一个文件出现“船长”一词很频繁(即TF很大),而且所有文件中出现“船长”一词不频繁(即IDF很小),那么“船长”就可以作为该份文件的特征值。如果如果所有文件中出现“船长”一次也很频繁(即IDF很大),那么虽然“船长”的TF很大,但仍无法区分出该特定文件。
LSH:局部敏感哈希。也是用来寻找相似数据的一种算法。它的意思就是:如果原来的数据相似,那么hash以后的数据也保持一定的相似性。它是用hash的方法把数据从原空间哈希到一个新的空间中,使得在原始空间的相似的数据,在新的空间中也相似的概率很大,并尽量使在原始空间的不相似的数据,在新的空间中相似的概率也很小。
特征哈希:是一种降维的方法。一个可以取N个不同值的类别特征,与一个可以去M个不同值的类别特征做笛卡尔乘积,就能构造出NM个组合特征,特征太多这个问题在具有个性化的问题里尤为突出。如果把用户id看成一个类别特征,那么它可以取的值的数量就等于用户数。把这个用户id特征与其他特征做笛卡尔积,就能产生庞大的特征集。会导致计算量过大,特征哈希法的目标是把原始的高维特征向量压缩成较低维特征向量,且尽量不损失原始特征的表达能力。特征哈希法可以降低特征数量,从而加速算法训练与预测过程,以及降低内存消耗。
归一化:是一种数据预处理阶段的一种简化计算的数据处理方式,即将离散的数据转换到0-1之间的小数。
以上的特征识别、相似识别的处理方法将产生用户身份、网络环境、文本、app、url、兴趣、地理位置、行为周期、设备等方面的维度。
识别:分为技术和模型两层。技术包括深度学习的模型、非线性模型、线性模型、图模型。
Deep Learning:带有隐藏层的神经网络。
GBDT:梯度提升决策树,是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。GBDT中的树是回归树(不是分类树),GBDT用来做回归预测,调整后也可以用于分类。GBDT的思想使其具有天然优势可以发现多种有区分性的特征以及特征组合。在淘宝的搜索及预测业务上发挥了重要作用。
随机森林:是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。随机森林与GBDT很类似,区别体现在:
- 随机森林采用的bagging思想,而GBDT采用的boosting思想。这两种方法都是Bootstrap思想的应用,Bootstrap是一种有放回的抽样方法思想。虽然都是有放回的抽样,但二者的区别在于:Bagging采用有放回的均匀取样,而Boosting根据错误率来取样(Boosting初始化时对每一个训练样例赋相等的权重1/n,然后用该算法对训练集训练t轮,每次训练后,对训练失败的样例赋以较大的权重),因此Boosting的分类精度要优于Bagging。Bagging的训练集的选择是随机的,各训练集之间相互独立,弱分类器可并行,而Boosting的训练集的选择与前一轮的学习结果有关,是串行的。
- 组成随机森林的树可以是分类树,也可以是回归树;而GBDT只能由回归树组成。
- 组成随机森林的树可以并行生成;而GBDT只能是串行生成。
- 对于最终的输出结果而言,随机森林采用多数投票等;而GBDT则是将所有结果累加起来,或者加权累加起来。
- 随机森林对异常值不敏感;GBDT对异常值非常敏感。
- 随机森林对训练集一视同仁;GBDT是基于权值的弱分类器的集成。
- 随机森林是通过减少模型方差提高性能;GBDT是通过减少模型偏差提高性能
KNN:K邻近算法,核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
SVD:奇异值分解算法,SVD可以用于降维,来做数据压缩和去噪。
bipartite graph:二分图。用户-商品之间,就是一个二分图。
community detection:社区发现算法,可以理解为一种聚类算法。整个网络中,同一社区内的节点与节点之间联系很紧密,而社区与社区之间连接比较稀疏。同一个社区中通常存在着较强的潜在兴趣关联或者线下社交关系。
强召回:基于规则。比如说用户有相同的账号登陆不同的地方。那么就认定这是同一个用户。这些是所谓的强召回,它可以非常准确地被判断出来。
弱召回:弱召回就是基于算法特征层的这些模型,有效地判断出所有信息是否真正属于同一个自然人。
特征迭代补充:当完成相似识别后,可以基于各自的特征,完善特征。
输出:以上的识别模型用于匹配服务。匹配服务的结果又作为输入,进一步完善整个体系(回流)。
标签工厂
标签工厂是以上技术架构的一个具体实例。数据源接入后,经过数据清洗、打通,首先会进行一定特征学习,然后进行打标,输出的就是标签数据。
大规模分布式知识图谱
大规模分布式知识图谱用于数据管理层面。阿里的数据接入量以ZB计算,很难一一做打标分析,那么通过建立知识图谱,在仅仅对常用数据打标,然后通过知识图谱的关系,将标签推理到其他冷门数据上。大规模分布式知识图谱它的底层还是上面那套技术架构,就是建立数据源、数据之间的相似度和特征关系,比如Owner特征、project特征、BU特征、NPL特征。
数据地图是基于此上的一个应用,即使用者输入一个查询关键词,根据知识图谱列出对应的表并生成对应的SQL。整个结果通过用户的确认去做回流优化。
