
disruptor的理解和应用
disruptor是一个大名鼎鼎的高性能的线程间的消息传递库,国内的资料不是很多。我近期在一个项目中使用了disruptor,有了一点理解,尝试着表达出来。可能不对,希望大家指正。
disruptor能干什么,不能干什么
disruptor是Java阻塞队列,比如 ArrayBlockingQueue的替代,它在性能上高于阻塞队列。disruptor是线程级的,无法在进程间共享,也不会提供持久化、灾备等系统级的功能。disruptor的用处是通过线程级的消息传递来做线程间的解耦,通过发布订阅模式,去实现线程级的并发。但disruptor不是HQ,MQ等消息队列容器的替代品,没有监控API,没有宕掉后的自动恢复机制,也不能被其他程序访问。
为什么用disruptor,而不是queue
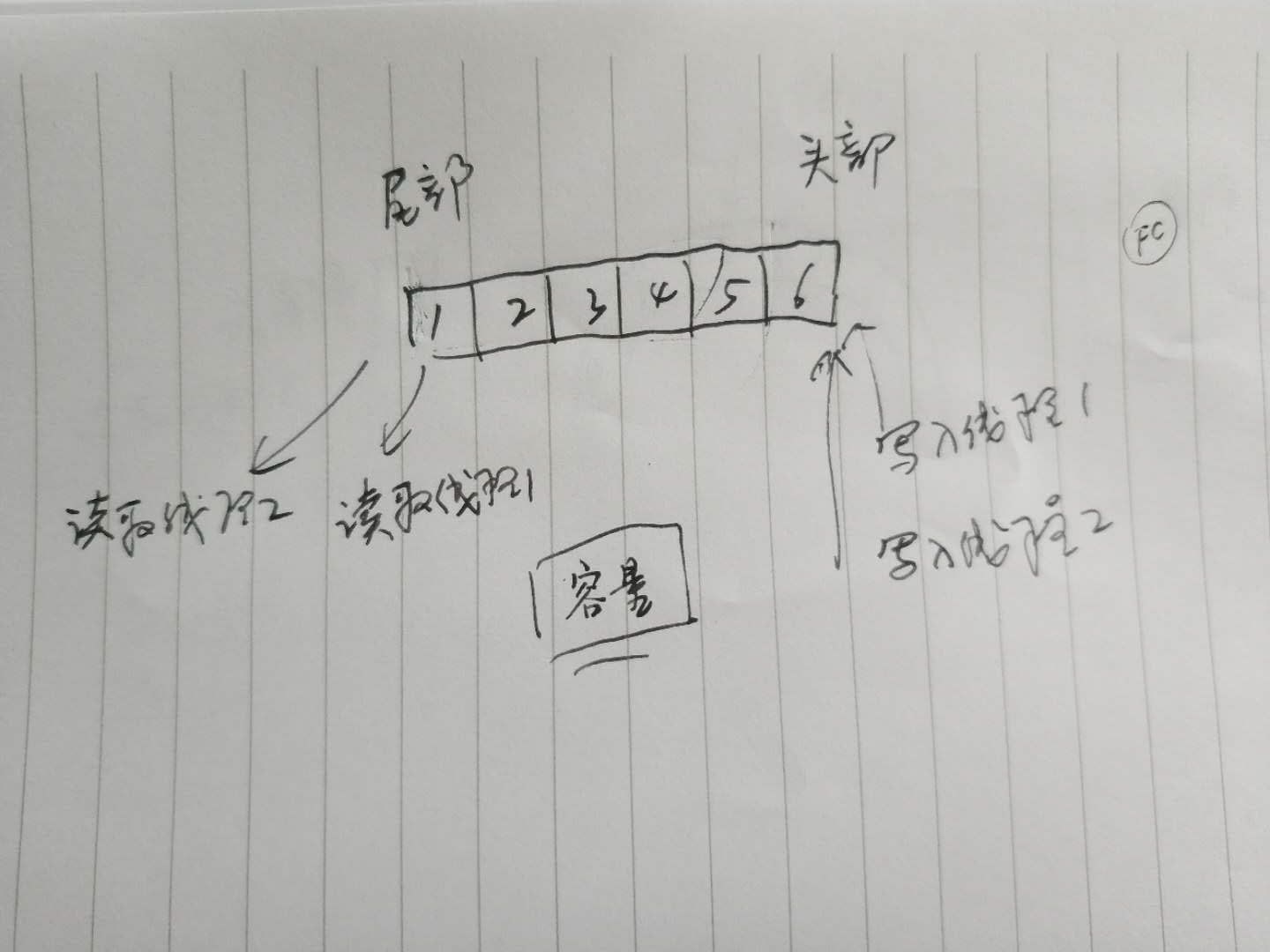
下图是queue的处理示意。queue的线程安全的读写,至少需要维持3个变量:尾部位置,头部位置,容量。写入线程需要争用头部位置,以便写入数据;读取线程需要争用尾部位置,以便读到数据(假定是不重复读场景);同时都要争用容量,容量满了不能再写,容量空了,也不应再读,读写成功后容量要加减。此时在三个争用位置处,就是性能瓶颈。
下图是disruptor的解决方案。disruptor 维持了一个固定大小的环型缓冲(ringbuffer)。用一个游标去跟踪这个ringbuffer的最大可用位置。读取和写入线程都分别通过读屏障和写屏障去读写数据。读写屏障通过特定的等待策略去唤醒对应线程。
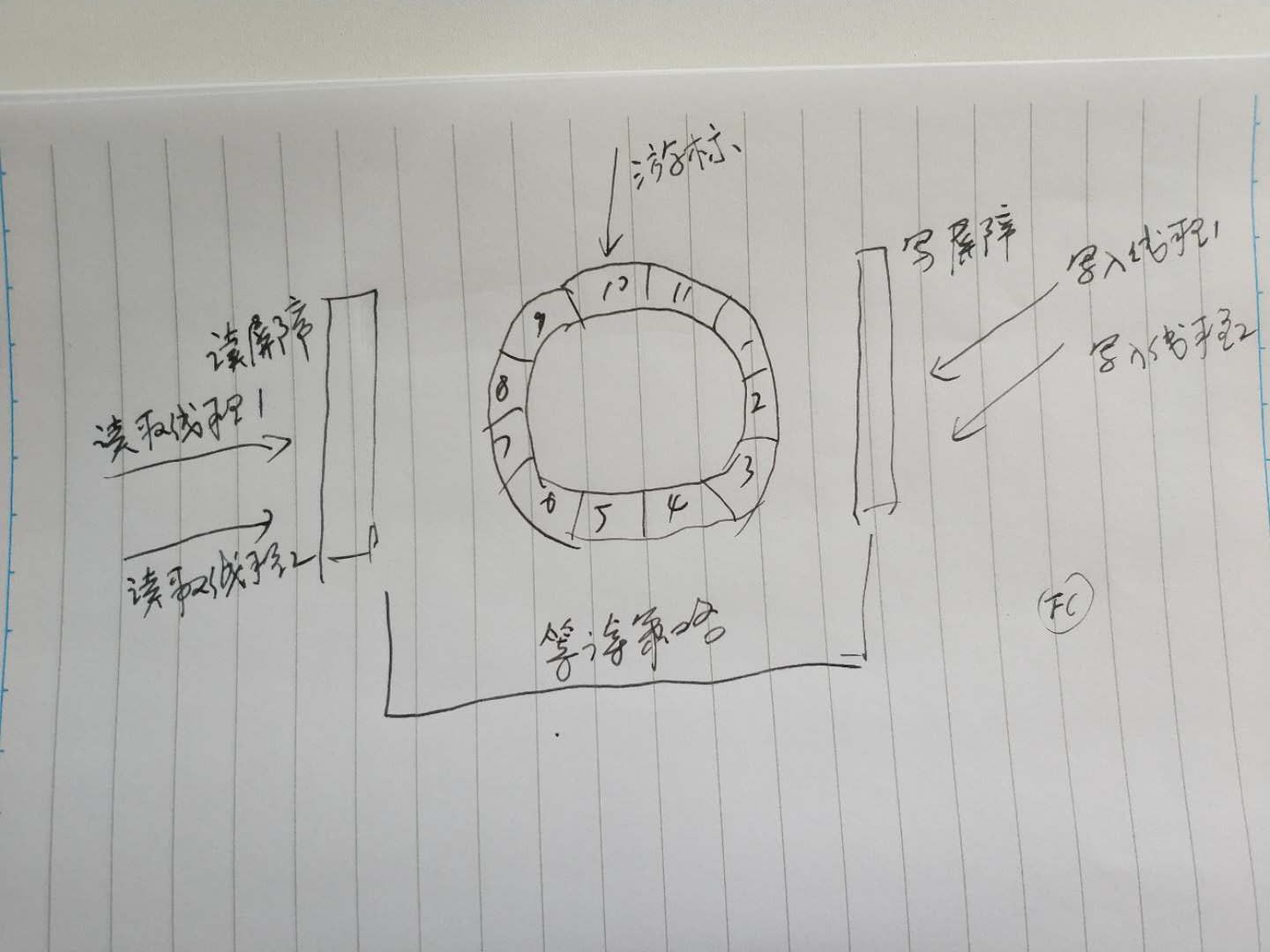
我们假定一个场景:当前的游标位置在10,读取线程1读取到8,读取线程2读取到1。此时写入线程1和写入线程2发起写入。写屏障根据游标位置,给写入线程1分配位置11,给写入线程2分配位置12(即位置1)。写屏障联合读屏障、游标三者的信息,很容易就得知现在位置11可用,位置12不可用,于是通知写入线程1写入,通知写入线程2等待。当写入线程1写入成功后,游标位置移到11,同时通知读屏障。读屏障告诉读取线程1、2当前最大可读位置是11。于是读取线程不需要再次请求就知道可用区域是多大。读取线程2完成位置1的读取后,读屏障收到了信息,告诉写屏障,写屏障将位置12可用的消息通知写入线程。写入线程2发现自己等待的位置已可用,进行写入。可见在整个过程中,各个线程是被唤醒的,没有锁没有冲突。所以别争用会拥有更高的性能。
disruptor的性能还有更底层的优化,涉及到CPU的CAS指令和缓存行填充技术。这篇文章讲的很好,可以查看。
使用时需要注意的问题
等待策略
disruptor的等待策略需要慎重选择,默认是BlockingWaitStrategy,这种策略是对CPU负载最小的,也就是我前面描述的例子,消费者等待被生产者唤醒,所以性能就最差。
最高性能的策略是BusySpinWaitStrategy ,这个策略是线程一直while(true),检查能不能干活了,所以CPU负载是最高的,其实大部分CPU都被while(true)消耗了。
一个折中的策略是YieldingWaitStrategy ,这个策略是线程while(true) 100次之后,休息一段时间。性能和CPU负载比较均衡。
在实际生产中,需要根据场景需要,调整策略。
缓冲池大小
缓冲池大小在官网上有个说法,说要匹配三级缓存的大小:cpu L3 cache的容量除以每个消息的大小。考虑到预留给其他应用,所以应该要小于这个值。
线程数
线程数到底设置成多少个比较高效呢?有个公式:
最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
线程CPU时间,是指线程中利用CPU去运算的时间。
线程等待时间,是线程中其他时间,比如IO的时间。
所以可以看出,线程等待时间所占比例越高,需要越多线程。线程CPU时间所占比例越高,需要越少线程
监控接口
disruptor提供的监控接口,只有一个ringbuffer.remainingCapacity()。它的返回值是可用容量。所以读写性能之类的都只能基于这个数据结合ringbuffer的size数据去算了。
一个例子
引入依赖
<!-- https://mvnrepository.com/artifact/com.lmax/disruptor --> |
定义消息实体
消息实体就是一个普通类,它就被作为对象放入到ring buffer中。
package com.winning.pipeline.queue; |
定义消息实体类的工厂类
disruptor的构造方法,指明必须使用消息实体类的工厂方法作为构造入参。所以必须得实现一个。
package com.winning.pipeline.queue; |
定义生产者
生产者的核心是使用ringBuffer.next()获取可用位置,使用MessageEvent event = ringBuffer.get(sequence);获取游标对应的槽位,设置后event对象后,通过ringBuffer.publish(sequence)发布出去。
package com.winning.pipeline.queue; |
定义消费者
消费者的onEvent方法会在有消息达到后调用。所以所有的消费逻辑都可以在这个方法里实现。
package com.winning.pipeline.queue; |
组装
前面消息实体、生产者、消费者都定义后了,接下来就是用他们来构造一个disruptor并运行起来。最终的messageProducer就是生产者句柄。在程序中可以使用messageProducer.onData()方法来发布消息。
// 事件工厂 |
在上面的代码中,是一个生产者一个消费者。如果要实现一个生产者多个消费者(不重复消费),那么需要定义一个 MessageConsumer数组,然后将第11行的代码修改为
disruptor.handleEventsWithWorkerPool(MessageCousumer[] 消费者数组) |
如果要实现一个生产者多个消费者(各自消费),那么可以修改11行代码为
disruptor.handleEventsWith(consumer1,consumer2) |
还有更复杂的场景,比如 A 和 B线程去消费,C线程必须等A 和B 消费完了之后再消费,这个时候代码可以改为
disruptor.handleEventsWith(A,B); |
关于多生产者的场景,官方是不建议的,下面的英文翻译成人话就是 最好的改善性能的方式之一就是坚持单一生产者原则,这个原则同样适用于disruptor。
One of the best ways to improve performance in concurrent systems is to adhere to the Single Writer Principle, this applies to the Disruptor.
END
欢迎留言讨论
